
At Razzball, our main goal is helping our readers and subscribers win their fantasy football leagues and entertain in the process. But now that the regular season is over, I am indulging in an ‘industry insider’ piece that will entertain only the dorkiest of you all. I will not take it personal if you just stop reading now or abandon ship before finishing. You have been warned…
So this marked my fourth year participating in the FantasyPros Weekly NFL Rankings Accuracy Contest. After a rough first year (91st), a stellar second year (5th), and a disappointed 3rd year (97th), I had a decent bounceback year in 2019 finishing in 46th place including a 9th place finish in QBs (2nd top 10 in 3 years) and my second straight 2nd place finish in Kickers (yay?). I was as high as 21st place overall with a couple weeks to ago and a brutal Week 16 knocked me down from 29th place.
If there is one constant among these volatile results, it is that I am by far one of the boldest rankers – i.e., my picks are consistently further from consensus than the average ranker. In 2019, I was the 4th boldest ranker out of 120. In 2018, I was 3rd boldest and I was the boldest ranker in 2017.
Despite not reaching the heights of my 2017 season, I have never felt better about my projection model and weekly process. But one question has nagged at me ever since I started the contest. It is a question I have probably thought about more than everyone on Earth combined.
How much should (if at all) the FantasyPros weekly rankings contest reward boldness (i.e., ranking players different from the consensus)?
Before I dive into this, please note that I really value the FantasyPros weekly in-season rankings contest and enjoy participating it immensely. I feel a kinship to everyone in the contest even the majority of with whom I never had an interaction. It is a big time commitment. I think it takes a lot of skill to succeed in the rankings and this post should not be seen as taking shots at either FantasyPros or any of the participants.
But I have a lot of thoughts on this subject and feel it is best to both share it to potentially affect change and to cleanse my brain so I can start deep diving into 2020 MLB with a clear mind.
Okay, here it goes….
Section 1: Considering The Best Interests Of All Stakeholders
So how should the FantasyPros in-season ranking contest value boldness? When thinking about how to structure a contest, you need to think about the best interests of all the stakeholders. For the FantasyPros ranking contest, I think there are three stakeholder groups:
- The contest host (FantasyPros)
- The audience (fantasy football players)
- The contestants (analysts/’experts’)
The Contest Host (FantasyPros)
As the contest host, the main objective for FantasyPros is to have the best quality consensus rankings. While creating a contest where 100+ fantasy football analysts rank players (for free!) is a great foundation for quality consensus rankings, FantasyPros faces a fundamental challenge in harnessing the ‘wisdom of crowds’. Here is a quote from the author of ‘The Wisdom of Crowds’:

Unfortunately, “think and act as independently as possible” is not really possible here. All rankers in FantasyPros have access to the consensus rankings. It has to be public as the #1 purpose of all these experts rankings players is to produce consensus rankings that can be used by FantasyPros site visitors. Even if it did not exist, rankings are published all throughout the week on various sites.
One can envision a contest run similar to DFS contents where all rankings are private prior to kickoff but this would not change the fact that ‘consensus’ wisdom is out there and it is in the best interest of each ranker (if not the consensus) to review their rankings vs the consensus. Even someone as divergent as me uses these consensus rankings to help QA my projections to identify potential errors throughout the week.
While complete independence in individual expert rankings is not realistic, developing a contest where diverse opinions are rewarded can still be accomplished or, as noted in “The Wisdom of Crowds”:
“Diversity and independence are important because the best collective decisions are the product of disagreement and contest, not consensus or compromise.” James Surowiecki
It is easy to see how diverse opinions – assuming they are informed by some level of expertise – make the consensus results better. Let’s say there are 100 analysts. If the rankings for Analyst #101 is extremely close to the existing consensus, they are not adding any value. If they identify the consensus is way too bullish/bearish on several players, they are adding value by slightly decreasing/increasing their consensus rankings.
So do the FantasyPros rules (you can find them here) reward disagreement and boldness vs consensus and compromise?
To win a given week? Yes. From my experience, the top finishes in a given week are often bold rankers. In Bruce Arians’ speak, winning a given week is a biscuit. And no risk it, no biscuit.
The real objective for all the rankers, though, is to win the season-long contest (the sum of Weeks 1-16 with your worst weekly scores in QB/RB/WR/TE set to league average). From my experience, the rules do not reward boldness at all. It is real cold if you’re bold.
To demonstrate this, I have run correlations on the final score of all participants vs their average rankings differences vs the consensus (aka ECR – Expert Consensus Rankings). Note the score is based on summing the differences between an expert’s projected player points (based on their ranks) and actual player points. It is like golf – smaller scores are better than greater scores. (A perfect correlation – e.g., how many pounds vs kilograms one weighs – is a 1.0. A perfectly negative correlation is a -1.0. A zero has no correlation)
| Correlation (r) b/w Expert Score and ECR Differential (Sum of QB/RB/WR/TE) | |
| 2017 | 0.34 |
| 2018 | 0.59 |
| 2019 | 0.53 |
For each of the last 3 years – and especially the last 2 years – the rankings correlated quite strongly with how little the ranker strayed from the consensus rankings.
Here are some easier statistics to digest:
- Of the 10 most conservative rankers in 2019, the average finish was 28th (out of 129 rankers) and included 4 of the top 10 rankers. Bottom finish was 70th. Second worst was 48th.
- Of the 10 least conservative rankers in 2019, the average finish was 93rd and included 3 of the bottom 10 rankers. Top finish was 46th (me).
Here is an example of the lack of diversity and disagreement often seen in the FantasyPros rankings. In Week 16, the Bucs had neither of their high target WRs in Mike Evans and Chris Godwin. Jameis Winston had been hot all 2nd half but also has a thumb injury. Their new #1 WR was Breshad Perriman who had flashed the last two games but was certainly not a known quantity. I am not the only analyst thinking this way…
Breshad Perriman has been in the league for 4 years & has essentially had 1 big game (where he only had 5 catches) yet a lot of fantasy players are acting like he’s Randy Moss in his prime. Don’t get me wrong, Perriman is a high ceiling WR2 play this week, but don’t get too cute.
— Jeff Ratcliffe (@JeffRatcliffe) December 20, 2019
If there was ever a time that a WR could justify a wide spread in ranks, this is it! His consensus rank among the 120+ rankers was #17. Below were Perriman’s rankings amongst the top 7 rankers going into Week 16:
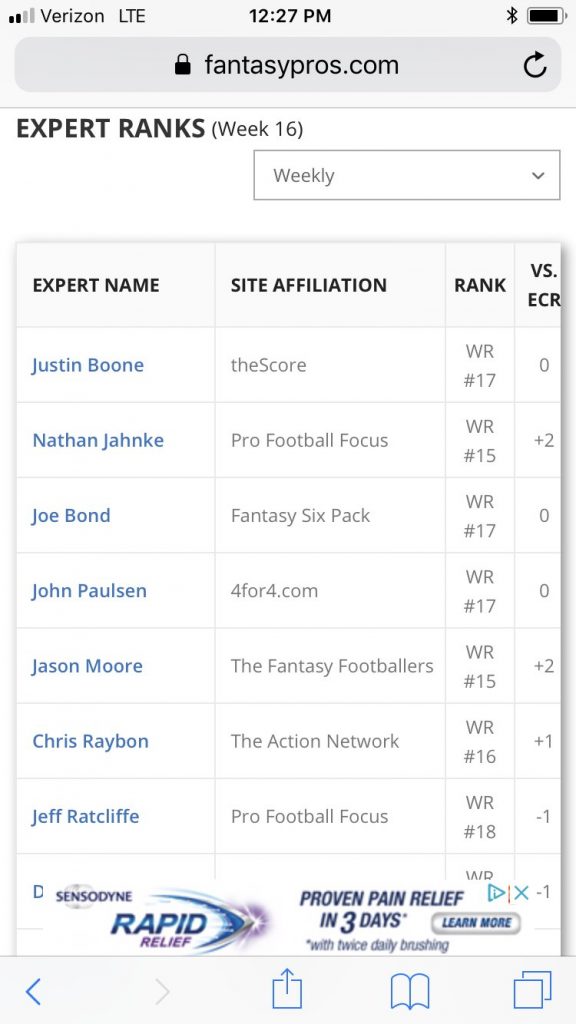
He actually finished around 17th so the consensus was right on Perriman. That is besides the point, though. Trust me, you can look at almost any QB/RB/WR/TE every week of the season and see similar homogenous rankings throughout the top of the rankings and there are plenty of times when it is dead wrong. The key point is that a healthy consensus-based system fosters diversity. The current system leads to rankings with the diversity of 19th century British royal gene pools.
Putting aside how much one values boldness, the correlation results demonstrate what many rankers have learned over time – there is significant incentive to conservatively rank players in his contest. This incentive has likely influenced behavior (consciously or subconsciously) and it does not hurt that ranking conservatively takes less work if one is making manual adjustments (do I REALLY have an opinion on WR30-34? nah, I will just leave them as is). This exacerbates the natural gravitational pull of having public consensus ranks and leading to a suboptimal and unnatural lack of diversity in player rankings.
I believe this to be counter to FantasyPros’ primary objective of producing the most accuracy consensus ranking. This is not the fault of the rankers given the incentives. The solution is to change the incentives to foster more diversity and disagreement vs rewarding consensus/’groupthink’.
The Audience (Fantasy Football Players)
The main objective for people who play fantasy football is slightly different than FantasyPros. Many use FantasyPros rankings. Many do not use their rankings but read and/or subscribe to one of the rankers publishing their rankings/projections on another site (which should mirror one’s FantasyPros rankings but do not have to).
These readership/subscription decisions (and the hiring decisions of the sites) may be influenced by how well the analyst has done in the FantasyPros rankings. If you do well in the contest, you would be a fool not to crow about it in your marketing materials.
The value of accurate in-season rankings is obvious if you play fantasy football. Better start/sit and add/drop decisions. The value of boldness is more subtle but if the average person in your league behaves similarly to the FantasyPros’ rankings, following a bolder ranker provides less competition on waivers and allows for more aggressive churn at the bottom of the roster since you can have more confidence of easily identifing weekly pickup targets (anyone who subscribes to our MLB tools knows this feeling).
I ran a poll to gauge how fantasy football players value boldness. It is by no means perfect (i.e., my followers probably skew a little bold, people might be more likely to ‘say’ they want bold than they actually do, I should have offered a 4th/5th option where Option A was somewhat/much more valuable) but I do think the results are generally reflective of active fantasy football players.
I could use some perspective on this.
Say there are two fantasy football analysts who provide rankings or projections
They are equally accurate based on some fair test
Analyst B rankings/projections diverge from ‘consensus’ significantly more than Analyst A.
Would you say….
— (((Rudy Gamble))) (@rudygamble) November 15, 2019
I think the value of boldness in rankings can also be seen in site/analyst marketing. Long-time Yahoo stalwart (and now free agent) Brad Evans is always touting his boldness/huevos. I tout mine in all our materials. Have you ever heard anyone tout their rankings or advice as “very similar to consensus but with a few little tweaks that incrementally improve your chances”? How about “Welcome to the Incremental Gains podcast. Wait until you see whom I say is the QB8 this week. One hint – he is currently ranked between QB7 and QB9”? (Of course not because incrementalism only sells if your customer base consists 100% of centrist Democrats.)
The Contestants (Analysts/Experts)
It is hard for a contestant to evaluate a contest without being biased by their own self-interest. OF COURSE I think boldness should be rewarded as it will reward me disproportionately. It is hard for me to expect anyone who thrives based on current scoring to want a major change. I could obviously game my rankings to the incentives and regress them heavily to the consensus but that is NOT how I want to win. My objective is to be the best in the industry at projecting fantasy football stats and I use the contest to get a little better every week. Fudging rankings to win does me no good in the long run.
Let’s take a step back and think about fantasy sports in general. Winning a redraft league takes skill/accuracy, luck, and taking risks. Assuming no major skill and experience differences within the league, we would expect riskier drafters to have higher ceilings/lower floors and more conservative drafters to have lower ceilings/higher floors. This makes for ideal gameplay.
This makes for ideal marketplaces too. It is one thing when someone becomes a billionnaire by bootstrapping and risking everything on a great idea. Imagine what our economy would look like if said risks meant you were less likely to become a billionnaire than those that went the conservative route and took a desk job at a big corporation?
Think about QB passing. Accuracy is vital for a QB but, when we analyze QBs, we balance a stat like completion percentage with a ‘boldness/risk’ stat like Yards per Completion or aDOT to make sure we do not overvalue a dink and dunk QB for completing 70% of their passes vs a downfield attacking QB who completes 60% but averages an extra yard per attempt. Or, in other words, a dink and dunk QB offers teams a lower ceiling/higher floor while a downfield attacking QB (think Fitzmagic) offers a higher ceiling/lower floor. (Yes, a great QB offers a high ceiling/high floor but that is typically because they are very successful in taking risks)
Keeping this in mind, let’s look at the top 10 finishers for 2017-2019 with the boldness percentile for each ranking spot – i.e., 100=100th percentile for boldness)
| Boldness Percentile For Top 10 Finishers 2017-2019 | |||
| 2017 | 2018 | 2019 | |
| Average | 28 | 30 | 21 |
| Median | 21 | 22 | 17 |
| 1st | 41 | 17 | 2 |
| 2nd | 31 | 34 | 19 |
| 3rd | 14 | 52 | 14 |
| 4th | 9 | 10 | 78 |
| 5th | 100 | 19 | 3 |
| 6th | 3 | 5 | 5 |
| 7th | 23 | 34 | 26 |
| 8th | 7 | 89 | 4 |
| 9th | 36 | 11 | 33 |
| 10th | 19 | 24 | 21 |
The median boldness percentile for the 2017-2019 top 10 finishers is consistently in the 17-22% range. This means they are significantly more conservative than the average ranker. For 2019, four of the top 10 are in the bottom 5% for boldness. Only four of the top 30 finishers over the past 3 years have even exceeded the 50th percentile in boldness.
Rather than lower ceilings/higher floors, my observation is that conservative rankers have higher ceilings AND higher floors while those that diverge more from consensus have generally lower ceilings AND lower floors.
Is it possible that the rankers in the bottom quintile (20%) in boldness are just better than the other 80%? There are clearly some smart names in the bottom quintile but I do not want to go down that rabbit holes. Instead, let’s think broader. Do you think that the top 10 finishers of high-stakes fantasy football leagues are in the 20th percentile for breaking from ADP? Do you think the top NFL QBs are typically in the 20th percentile for bold decisions? Do you think the top 10 hedge fund managers are the ones that invested the most in index funds? (If you answered yes to any of those questions, I give up)
Putting aside one’s opinions on the value of boldness, I think there is a valid argument these results highlight that the risk/reward relationship driving fantasy football gameplay, effective marketplaces, and QB analysis is noticeably absent in the FantasyPros contest results.
Summary of Stakeholder Best Interests In Regards to Boldness
- It is in FantasyPros best interest to foster diversity and disagreement in rankings to produce the most accurate in-season player rankings.
- It is in the fantasy football audience’s best interest (and they want) to have some degree of boldness in the player rankings they consume for less competition when making in-season pickups
- It is in FantasyPros’ contestants’ best interest to reward boldness for more satisfactory gameplay that mirrors the risk/reward relationship of season-long leagues vs rewarding ‘dink and dunk’ rankings.
Section 2: So What Could/Should Be Done?
There are a surprising number of constraints when thinking through the feasibilty of any solution. Let’s just say the ideal solution would require:
- No extra work for contestants
- Minor development by FantasyPros
- Can be calculated weekly (vs waiting until end-of-season)
- Can be calculated for each position (e.g, QB, RB, WR, TE)
- Cannot be easily gamed
I think one key based on the above is that the solution has to be an extension of FantasyPros’ methodology vs a whole new methodology.
My suggested approach came to me during the 2019 season and is quite straightforward in concept (the math gets a little hard but I won’t bore you with that).
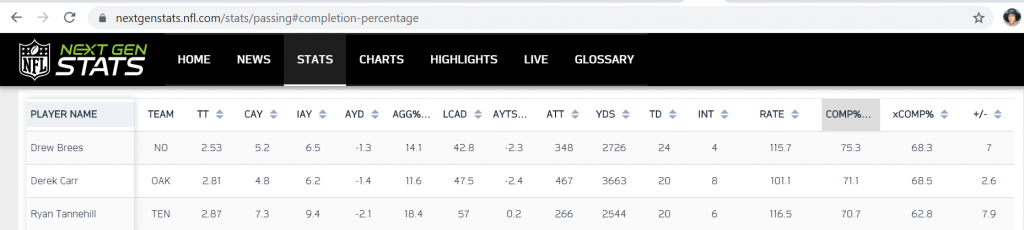
If we go back to the QB analogy, measuring a QB by just Completion PCT is not ideal. But NFL Next Gen Stats developed an Expected Completion Percentage metric that adjusts based on the ease/risk of completing each reception. 
For the Accuracy test, I ran regression analyses to create an Expected Accuracy Score per position based on an analyst’s average weekly difference vs the consensus. An analyst’s Expected Accuracy Score minus their Actual Accuracy Score creates the equivalent of a ‘Completion Percentage Above Expectation’. This would represent a fully risk-adjusted Accuracy Score.
The Twitter poll I ran was evenly split between those thinking boldness was 1) very valuable, 2) somewhat valuable, and 3) not valuable at all. A full risk-adjusted score is akin to believing risk is very valuable. To create a ‘somewhat valuable’ score, I multiplied the current Accuracy Score * 2 and then subtracted the Expected Score. This represents a half risk-adjusted Accuracy Score.
A zero risk-adjusted Accuracy Score is easy. It is the current FantasyPros Accuracy Score.
Below are the FantasyPros 2019 Accuracy results for Full/Half/Zero risk adjustment.
Some notes:
- The correlation between ECR differentials and Accuracy Scores are as follows:
- Zero: 0.53
- Half: 0.30
- Full: ~0
- Under ECR Differential
- Avg = This is the weekly average differential of the rankers’ ranks vs consensus and is calculated by FantasyPros
- %ile = This is the ‘boldness’ percentile (0-100) based on the Avg column
- STDEV = This is the Standard Deviation of the Avg. The median (aka the middle value) is zero. Anything negative means the result is below the median. This is a better way to view boldness vs percentile as there is a much bigger difference between, say, the 70th and 90th percentiles vs the 50th and 70th.
- Accuracy Score
- Actual (“Act”) is calculated by FantasyPros. Lower = better.
- Expected (“Exp”) is calculated by me based on the STDEV of the ECR Differential and the extent of the correlation between ECR Differential and Accuracy Scores
- Diff is Expected Score – Actual Score. Higher = better.
- ‘Actual – Diff’ is the “Half” risk adjustment. Lower = better (note: since Diff is Expected – Actual, this is identical to Actual * 2 – Expected)
- The table is sorted by FantasyPros current rankings (i.e., Zero column)
Let’s first look at the ‘Diff’ column. It is important to note that any analyst who finishes in the top 10 – even if they are very conservative – have a positive number here. They are all ranking players more successful than expected based on their boldness.
But we can see that Chris Raybon of The Action Network, who finished 4th in the contest, has a significantly higher Diff score than the others in the top 10. This is because he was significantly more bold than the others in the top 10. Looking at the first two columns (the Full and Half risk-adjusted ranks), Raybon is the new #1. While his Accuracy Score is 36 points worse than the winner (Justin Boone), his expected score was 200 points worse since his ranks diverged from consensus significantly more. In Next Gen Stats terms, Justin Boone had a 2019 Derek Carr year (great Comp%, very good YPA (7.8)) while Chris Raybon had a 2019 Ryan Tannehill year (mildly less great Comp% but insane YPA (9.56) because he was attempting more difficult passes (as seen in the +/- advantage).
Let’s zoom in on the analysts ranked at #46 (myself) and #44 (whom I am not naming in here so this post isn’t what shows up when Googling his name). I was extremely bold and much better than expected (+325 Diff) given how much I deviated from consensus. The #44 ranker was very conservative and well below expected (-61 Diff) given how closely he stuck with consensus. If one built a random rankings adjuster each week to match our ECR differentials, it would be very unlikely to end up with a +325 in Diff. With all due respect to the #44 ranker, this random rankings adjuster would have beaten his -61 differential a lot more than 50% of the time. Do these seem like equally valuable rankings/accomplishments?
When ranking based solely on the Diff column (the ‘Full’ risk adjusted ranks that is in the first column/yellow), there are some massive changes vs the overall rankings (third column/white). I go all the way from 46th to 2nd. Staff Rankings of DailyRoto go from 55th to 4th. Justin Boone goes from 1st to 15th. How/why does that happen? Take a look at the STDEV column. Of the top 70 finishers, 68 finishers range from -1.3 to 1 standard deviation from the median on boldness. DailyRoto and I are 2.3 standard deviations from the median. To give some perspective, there are 12 analysts besides us that are 1.5+ STDEVs and the average finish is 105th. Conversely, Justin was the third most conservative ranker in the contest (-1.1 standard deviations) so adjusting for risk makes his performance look a little less stellar.
The ‘Half’ adjusted rankings (second column/orange) have a milder impact. We still see some major changes in the top 10 with only 6 of the current 10 staying in and moving down as much as 9 spots. Mike Tagliere of FantasyPros jumps from 12th to 2nd thanks to being roughly 1.5 STDEVs bolder than most of the existing top 10. The existing 1st/2nd place finishers (Justin Boone and John Paulsen) slide back but only to 3rd/4th place. I jump up to 11th from 46th which is a huge jump/reward for being successfully bold but not nearly as high as 2nd.
From a gameplay (and market acceptance) perspective, I think the ‘Half’ risk-adjusted rankings are a little better. While bold rankers are still at a statistical disadvantage (as evidence by a positive correlation between ECR Differential and Accuracy score), the advantage has been decreased (correlation down from 0.53 to 0.3). The net impact is a mildly lower ceiling/floor for conservative rankers and a mildly higher ceiling/floor for bolder rankers.
Additionally, the ‘Half’ rankings enable it so that any ranker across the conservative/boldness spectrum has a fair shot at finishing #1 as long as you are significantly better than what would be expected based on your boldness. Whereas the current system disincentivizes boldness, this system provides enough incentive to diverge from consensus (whether it is a very bold +15/-15 or minor +2/-2 adjustment) without rewarding boldness for the sake of it.
Lastly, the Half rankings mirror the point that boldness somewhat matters when it comes to rankings which my poll suggests is the middle position among the fantasy football audience.
(Note: In regards to the last requirement of ensuring this cannot be gamed. If boldness was incorporated into the rankings, thought would need to go into how one measures it. ECR Differential worked well for this test because it has never been a ranking variable.)
Section 3: The Revisionist Rankings
I have applied the ‘Full’ and ‘Half’ risk-adjusted methodology to 2017, 2018, and 2019 rankings.
Some notes:
- Using the ‘Half’ risk-adjusted rankings, a different winner was crowned vs the actual contest in each of the 3 years:
- 2019 – Chris Raybon
- 2018 – Dalton Del Don
- 2017 – Rudy Gamble
- Top 5 Single Season Full Risk-Adjusted Scores (Difference of Expected – Actual Scores) 2017-2019
- #1 – Rudy Gamble 2017 – 496
- #2 – Chris Raybon 2019 – 337
- #3 – Sean Koerner 2017 – 327
- #4 – Rudy Gamble 2019 – 325
- #5 – Dalton Del Don 2018 – 309
- Top 10 Average Full Risk-Adjusted Scores (Difference of Expected – Actual Scores) 2017-2019
| Analyst | Seasons | Average |
| Rudy Gamble – Razzball | 3 | 319 |
| Sean Koerner – The Action Network | 3 | 219 |
| Staff Rankings – Daily Roto | 3 | 204 |
| Heath Cummings – CBS Sports | 3 | 195 |
| Brett Talley – Fantasy Alarm | 3 | 164 |
| Mike Tagliere – FantasyPros | 3 | 162 |
| Chris Raybon – The Action Network | 2 | 155 |
| Robert Waziak – The Fantasy Footballers | 3 | 154 |
| Jared Smola – Draft Sharks | 3 | 152 |
| John Paulsen – 4for4.com | 3 | 147 |
- Top 10 Average Half Risk-Adjusted Scores 2017-2019
| Analyst | Seasons | Average |
| Sean Koerner – The Action Network | 3 | 15982 |
| Justin Boone – theScore | 3 | 16060 |
| Rudy Gamble – Razzball | 3 | 16063 |
| Robert Waziak – The Fantasy Footballers | 3 | 16072 |
| John Paulsen – 4for4.com | 3 | 16074 |
| Andy Holloway – The Fantasy Footballers | 3 | 16105 |
| Jake Ciely – The Athletic | 3 | 16109 |
| Pat Fitzmaurice – The Football Girl | 3 | 16110 |
| Jason Moore – The Fantasy Footballers | 3 | 16122 |
| Jared Smola – Draft Sharks | 3 | 16127 |
- Revisionings Standings (2017-2019)